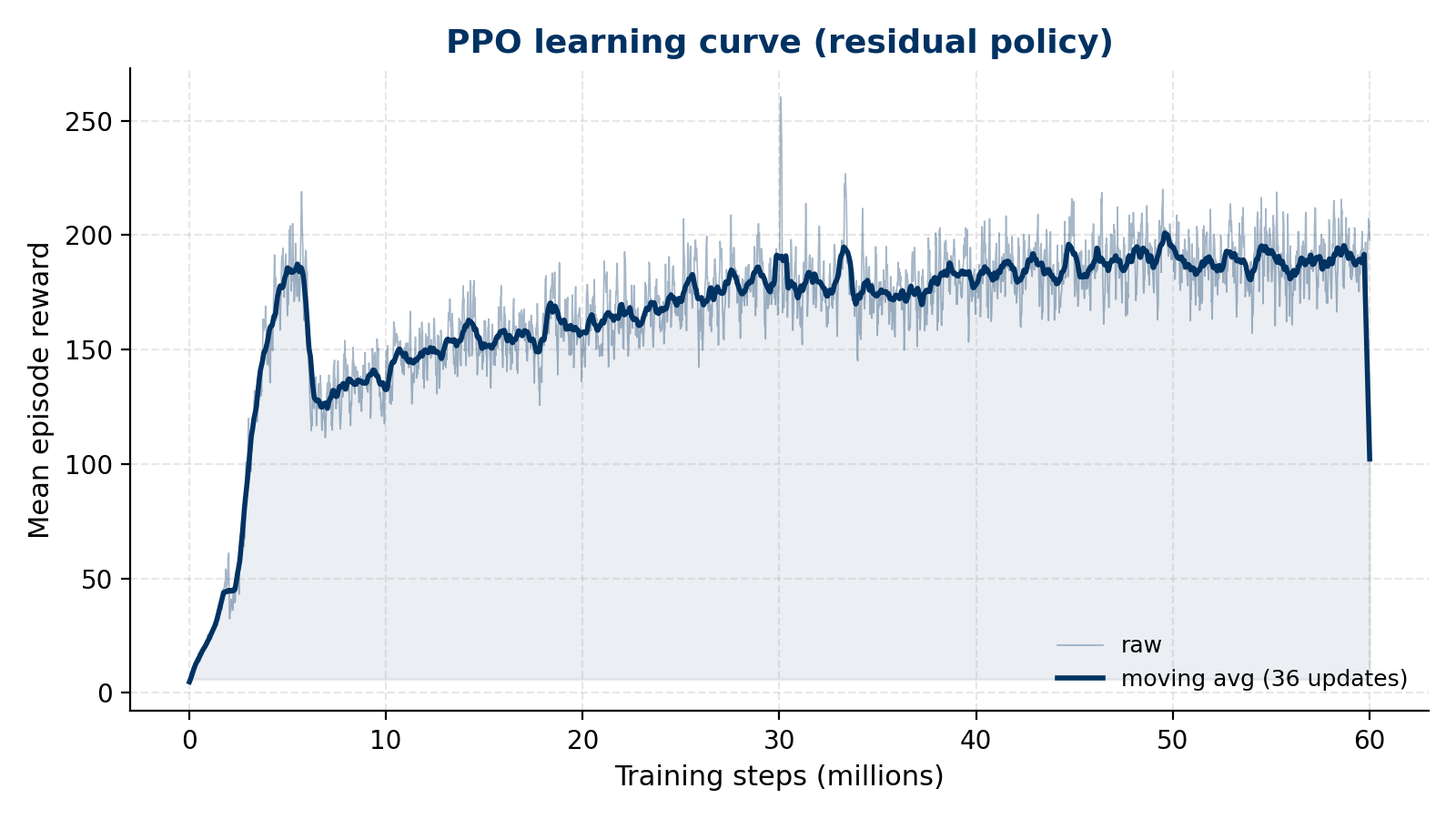
§ 5Discussion
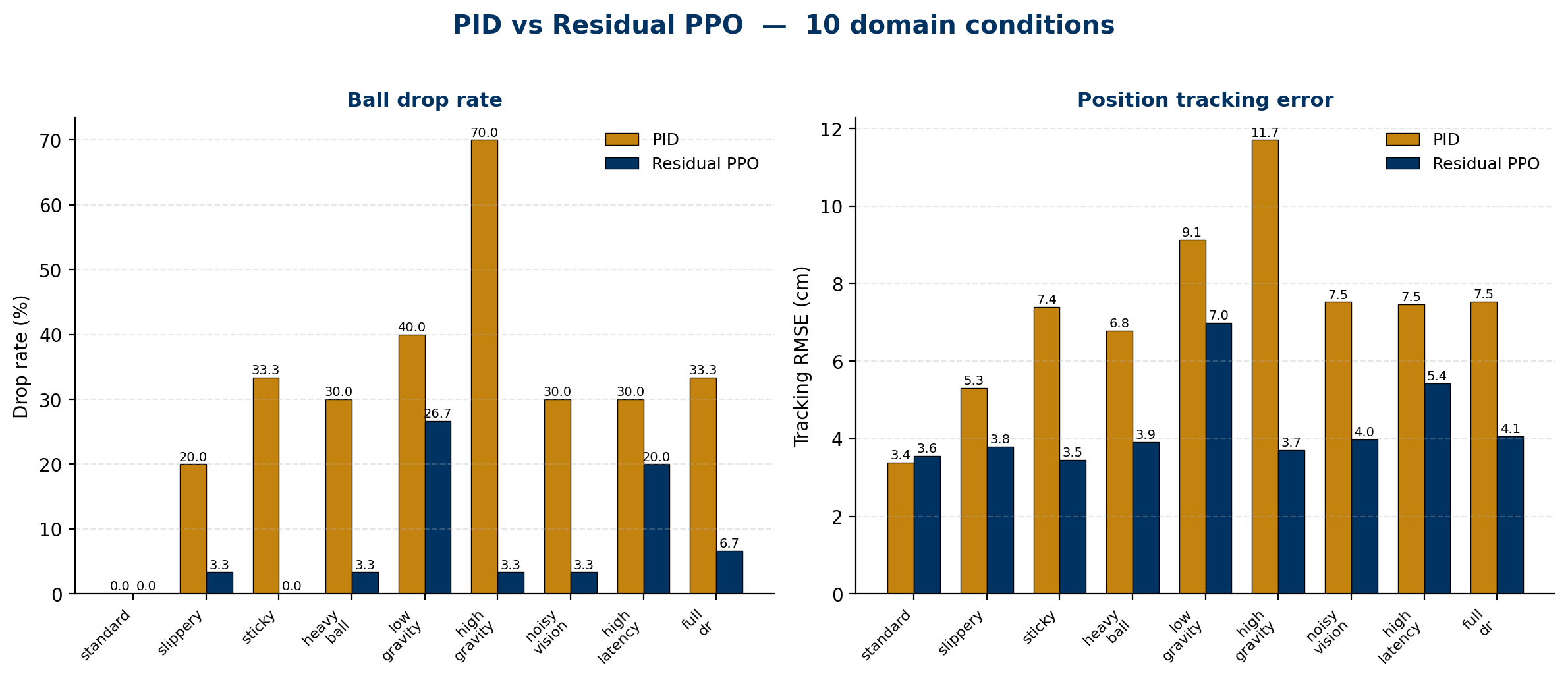
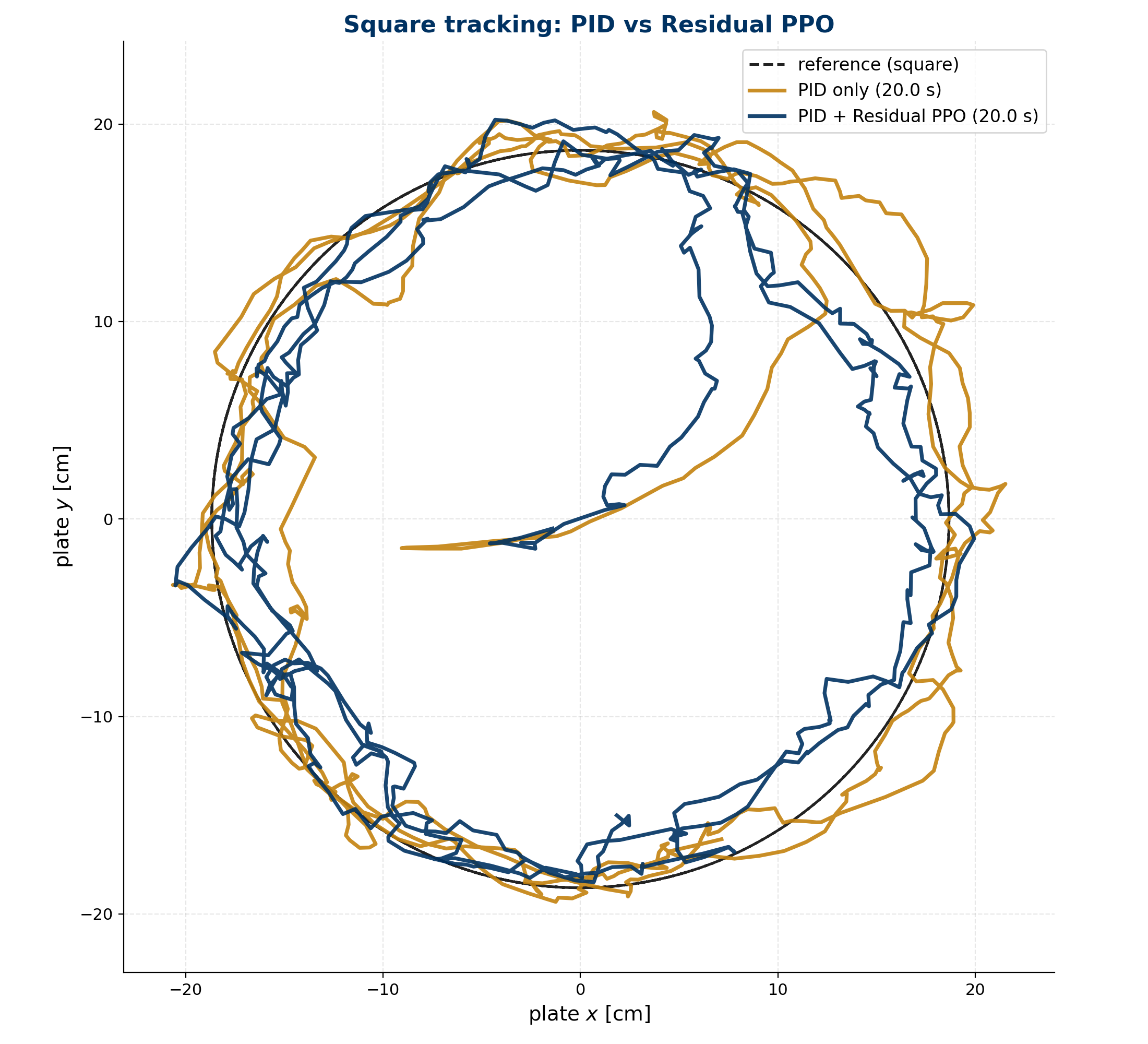
The PID was tuned at the nominal operating point and tracks the reference
well there. Its gains are fixed, so when the simulator moves away from
those conditions the closed-loop dynamics no longer match what the gains
were chosen for and the ball is lost. The residual policy was trained
across the whole envelope under domain randomisation; its drop rate stays
low across every perturbed condition, and it recovers most of the tracking
accuracy that the fixed-gain PID loses off nominal.
The smallest improvement is under weaker-than-nominal gravity. The ball
moves slowly, the dynamics evolve on a longer effective time horizon, and
the constant-velocity prior of the Kalman filter is least accurate in this
regime. The remaining error is dominated by estimation rather than
control, so both controllers degrade together.